# 运行模式-完全集群
# 1. 集群部署规划
| · | big002 192.168.2.10 | big003 192.168.2.11 | big004 192.168.2.12 |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryName NodeDataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
# 2. 配置集群
# 2.1 核心配置文件(core-site.xml)
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://big002:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/mnt/tmp/hadoop/data/tmp</value>
</property>
1
2
3
4
5
6
7
8
9
10
2
3
4
5
6
7
8
9
10
# 2.2 HDFS配置文件
# 2.2.1 hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_231
1
# 2.2.3 hdfs-site.xml
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定 Hadoop 辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>big004:50090</value>
</property>
1
2
3
4
5
6
7
8
9
10
2
3
4
5
6
7
8
9
10
# 2.3 YARN 配置文件
# 2.3.1 yarn-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_231
1
# 2.3.2 yarn-site.xml
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>big003</value>
</property>
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 2.4 MapReduce配置文件
# 2.4.1 mapred-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_231
1
# 2.4.2 mapred-site.xml
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>big002:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>big002:19888</value>
</property>
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 3. 分发集群配置文件
[leichu@big002 ~]$ xsync /usr/local/hadoop-2.10.0/etc
1
# 4. 群器集群
# 4.1 配置 slaves
vim /usr/local/hadoop-2.10.0/etc/hadoop/slaves
## 输入数据节点所在的主机名称
big002
big003
big004
## 配置文件分发
[leichu@big002 ~]$ xsync /usr/local/hadoop-2.10.0/etc/hadoop/slaves
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
# 4.2 格式化 NameNode
[leichu@big002 ~]$ hdfs namenode -format
1
# 4.3 启动 HDFS
## 注意:HDFS 只能在 NameNode 所在的主机上启动
[leichu@big002 ~]$ start-dfs.sh
1
2
2
# 4.4 启动 YARN
## 注意:YARN 只能在 ResourceManager 所在的主机上启动
[leichu@big003 ~]$ start-yarn.sh
1
2
2
# 4.5 启动 历史服务
[leichu@big002 ~]$ mr-jobhistory-daemon.sh
1
# 5. 集群测试
# 5.1 上传大文件
## 在 HDFS 上创建测试目录 leichu
[leichu@big002 ~]$ hdfs dfs -mkdir -p /leichu
## 上传
[leichu@big002 ~]$ hdfs dfs -put /leichu/hadoop-2.10.0.tar.gz /leichu
## 查看测试目录下的文件
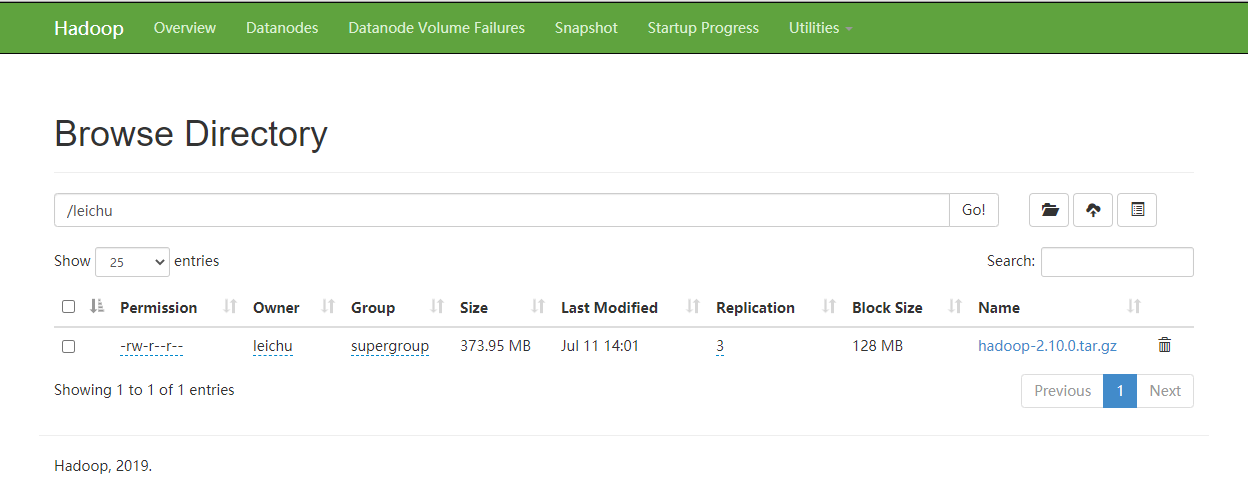
[leichu@big002 hadoop]$ hdfs dfs -ls /leichu
Found 1 items
-rw-r--r-- 3 leichu supergroup 392115733 2020-07-11 14:01 /leichu/hadoop-2.10.0.tar.gz
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
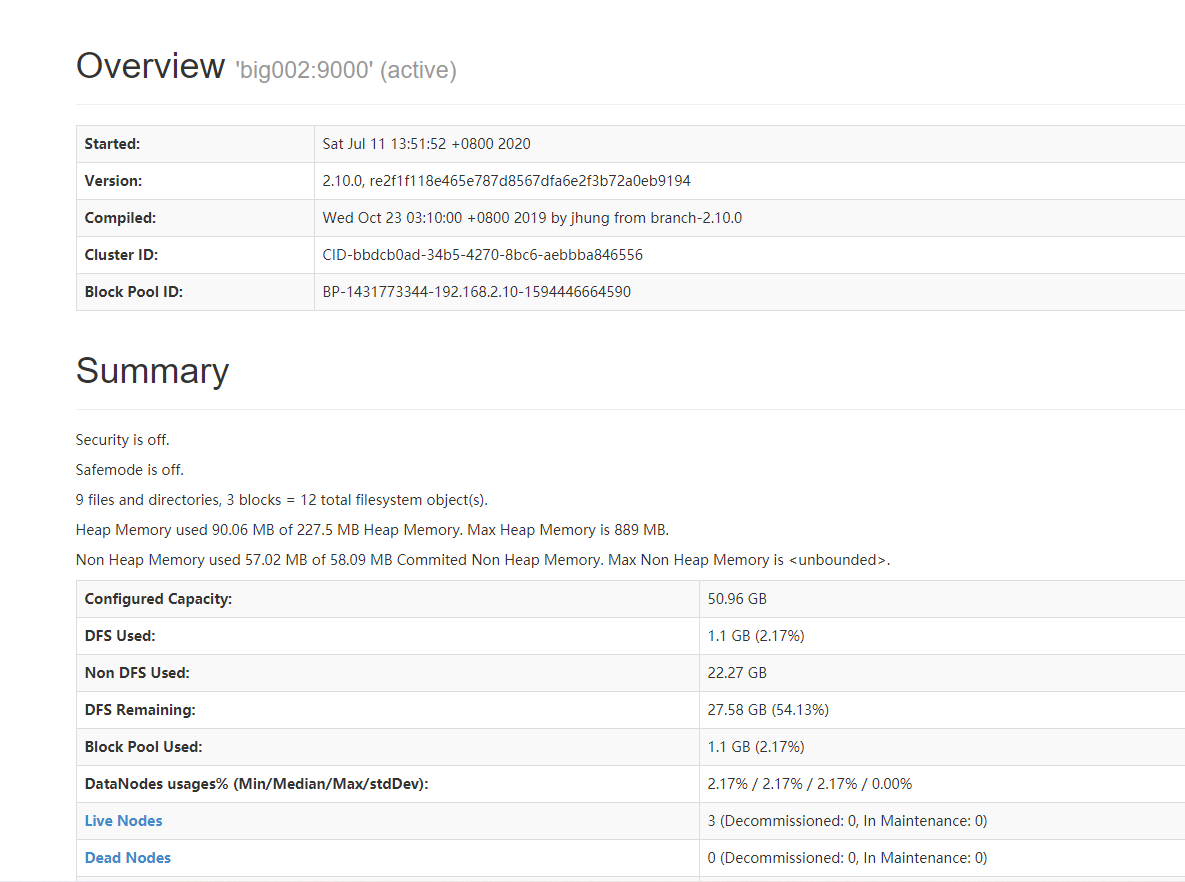
# 5.2 web 端查看
## Hadoop 首页
http://big002:50070
## HDFS 首页
http://big002:50070/explorer.html
## 历史服务首页
http://big002:19888/jobhistory
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8

# 6. 关闭集群
## 关闭 big002 上的 HDFS
[leichu@big002 ~]$ stop-dfs.sh
## 关闭 big003 上的 YARN
[leichu@big003 ~]$ stop-yarn.sh
## 关闭 big002 上的 历史服务
[leichu@big002 ~]$ mr-jobhistory-daemon.sh stop historyserver
1
2
3
4
5
6
2
3
4
5
6